# Perceptron
One of the first artificial neural networks. A perceptron is an algorithm for supervised learning with the goal of taking a list of inputs and classifying them into one output or another. It is identified as a single neuron in this image. Is it always?
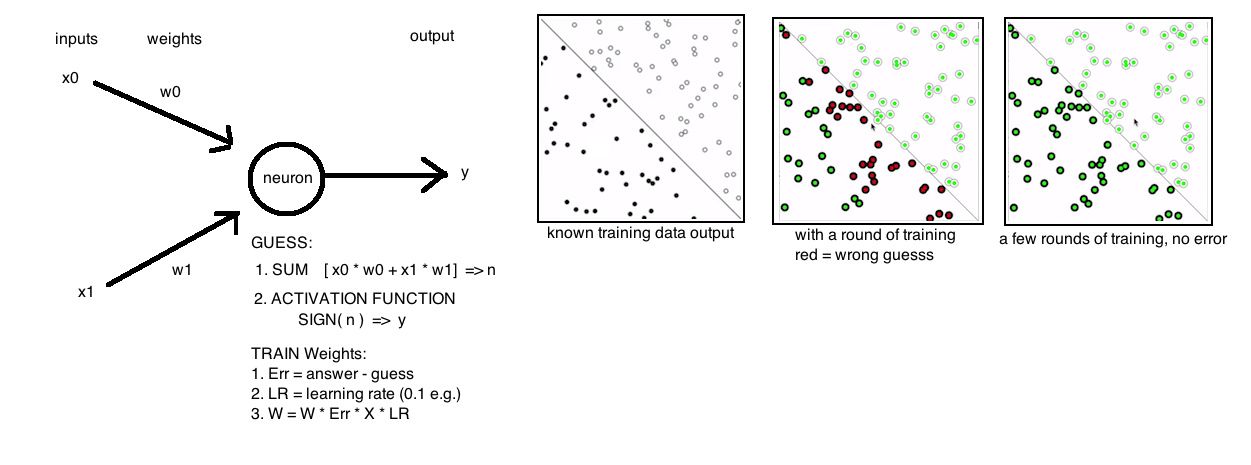
# Example
In this picture we have a perceptron on the left that will take a list of points in a 2d plane and will classify them as either on one side of a line or the other. The perceptron has two inputs, one for each point in the 2D list of points and one output, for which side of the line that point should be on
*Supervised learning* is the process where you provide the AI a list of inputs with known outputs. The AI makes a guess at an input and you specify whether it was correct or incorrect. If it was correct it will strengthen that guessing if it was incorrect it will weaken that guessing. This transformation of guessing is called Radiant Descent.
1. Provide perceptron with inputs for which there is a known answer.
2. Ask the perceptron to guess an answer.
3. Compute the error. Right or wrong?
4. Adjust weights according to error.
5. Return to Step 1 and repeat.
So in our example the neuron has two inputs. Each input has a weight, the neuron is going to create the "SUM" of the inputs as its first step.
X0 = input 1 (or X on our Coords)
X1 = input 2 (or Y on our Coords)
W0 = weight of the input 1 path
W1 = weight of the input 2 path
## Step 1: Sum the Inputs
Step 1 is to sum the inputs.
The neuron will sum them the following way: `( X0 * W0 + X1 * W1)`
It will add the inputs times their weights, for every input attached to the neuron.
Step 1: SUM the inputs `( X0 * W0 + X1 * W1 + ... XN * WN)`
## Step 2: Activation Function
Step 2 is the activation function, where we take the sum and we conform it to an output. The sum of those numbers could be large, and ultimately we are want to conform them to some classification, like -1 and +1. So we specify an activation function.
An example is the SIGN() function which will take any arbitrary number and convert it to either -1 or +1.
From these two steps our perceptron can make a guess from two inputs for an output.
```
class Perceptron {
float[] weights;
Perceptron(int n) {
// Set random weights
weights = new float[n];
for (int i = 0; i < weights.length; i++) {
weights[i] = random(-1,1);
}
}
int guess(float[] inputs) {
float sum = 0;
for (int i =0; i < weights.length; i++) {
sum += inputs[i] * weights[i]; // SUM step
}
int output = sign(sum); // ACTIVATION step
return output;
}
}
```
*How do you pick the weights?* This is the big piece of the conversation. In supervised learning you must tweak the weights until you see the learning you desire. Start with random numbers maybe.
## Create Known Dataset
Lets create a known data set that has inputs and outputs that are correct. In our example we could define that there is a line `y = x` (diagonal) and everything about the line is +1 and everything below the line is -1.
We can then write a program to generate tons of points with outputs that are correct. This would be our training data.
```
int x = Random();
int y = Ranfom();
int label = 0;
if (x > y) {
label = 1;
} else { // x == y too
label = -1;
}
```
## Adjusting Weights
Take the training data generated and pass it into the Perceptron for it to make a guess.
We will have the Guess and the Answer. With both of these things with `error = answer - guess`, the difference between the correct answer minus the guess.
We want to find the optimal weights. `W0 = W0 + delta(W0)` How do we calculate the delta weight?
We use the *Gradient Descent* to calculate this. An example is a car, it has a destination and a velocity. The velocity it is traveling may not be toward the destination. So we have a Destination Velocity and a Current Velocity. The steering formula will be the destination velocity minus the current velocity. Adding this steering to the current velocity causes me to turn and approach the destination.
The `error = label - guess`
So the `delta(w0) = error * x0`
And the `new weight = weight + error * input`
## Training the Perception
So prior our perceptron could make a guess. Now we want to train if that guess is correct and change weights with inputs and a known answer.
Weights will only be adjusted if the error != 0.
```
// inside Perceptron class
void train(float[] inputs, int target) {
int guess = guess(inputs); // get guess
int error = target - guess; // calculate error
for (int i =0; i < weights.length; i++) {
weights[i] += error * inputs[i]; // tune the weight by adding the delta
}
}
```
Now, in the concept of steering it is important that we want to steer toward our correct guess gradually so we do not overshoot the desired value and get caught jumping back and forth. Like steering the car, we dont want to oversteer and then correct back and oversteer again. So we need to include a **learning rate**.
`delta(w0) = error * x0 * learning_rate`
```
// inside train function
float learningRate = 0.1;
for (int i =0; i < weights.length; i++) {
weights[i] += error * inputs[i] * learningRate; // updated to learning rate
}
```
We can adjust the learning rate to not oversteer. Now we should be able to train the perceptron using our generated training data and the new train function.
```
Perceptron perceptron = new Perceptron(2); // two points
// get a bunch of training data as points
foreach (Point pt in trainingPoints) {
float inputs[] = {pt.x, pt.y};
perceptron.train(inputs, pt.label);
}
```
In this example we are actually training the Perceptron to provide the formula to the slope of data we are feeding it. It is learning the function for the slope we have provided with inputs and labels to check against.
Our example `y = x` is a straight diagonal line, but we could also train for other slopes (or functions).
## Expanding our Function Testing
In our example we are explicitly training for X = Y and testing if something is above or below that line. But we can expand upon this with a training function but extracting how we train.
```
float targetFunction(float x) {
return 2 * x + 1.5; // Y = M*X + B
}
float x = Random();
float y = Random();
float lineY = targetFunction(x); // get where Y is at on our function for X
int label = 0;
if (y > lineY) {
label = 1;
} else {
label = -1;
}
```
## The Zero Problem and Bias
In our example, if we feed in 0,1 into our Perceptron we will always produce a 0 output because multiplying by the weights and summing still produces 0. Because of values that produce a zero the perceptron cannot guess toward an answer.
In order for use to overcome this, we need to introduce a *bias* into our neuron.
A bias introduces an additional weight to the calculation. In order to train our perceptron with a bias, we need to increase its weight count and provide the bias in its training.
```
Perceptron perceptron = new Perceptron(3, .01); // two points + bias, .05 learning rate
int bias = 1;
// get a bunch of training data as points
foreach (Point pt in trainingPoints) {
float inputs[] = {pt.x, pt.y, bias};
perceptron.train(inputs, pt.label);
}
```
## Summary
1. Inputs plus a Bias are connected to the Perceptron
2. Each input has a weight for its connection
3. The neuron multiples the inputs by their weights and sums them
4. It runs the sum through an activation function
5. The result is an output as a guess
6. The guess is compared to the answer and error is calculated
7. Weights are adjusted by how incorrect the guess was
9. After a series of training the Perceptron has a very accurate internal guess
## Working Perceptron